
Toxic Algorithms: Neural Networks, Bias, and Addiction
Neural Networks control our information exposure online


Neural Networks influence the content that is shown to us. Most platforms use NNs including Facebook, TikTok, Reddit, Substack, Instagram, Google, ChatGPT, with YouTube (Google) an early pioneer, in 2016 integrating NNs into their platform to influence video recommendations.
In Part I, I explain the history of Neural Networks (NNs) and what they are. Basically, NNs are a long-standing computer algorithm that works to recognize patterns and connections in datasets. They are very popular in data science, software development (especially AI), and in neuroscience.
Why are Neural Networks popular?
By the mid 2000s, NNs were losing ground to other algorithms that were more mathematically elegant and had better inherent corrections against bias like support vector machines (SVMs), random forest models, and gradient boosting. (I can personally attest that SVMs were superior in performance than NNs in a research project that I did a few years ago). The lack of databases to train NNs and lesser computational power was a disadvantage for NNs. With the advent of the World Wide Web large, digitized datasets were readily available. As we know, Internet algorithms in the ‘90s were extremely simple, sometimes listing sites alphabetically or categorized manually by human editors. More efficient categorization systems like Google’s Page Rank System helped improve the accessibility and organization of this information which included videos, text files, scientific papers, audio files, and even harder to parse, images.
But how could this information be analyzed comprehensively?
It all came down to a 2012 competition

Li, Fellbaum, and Russakovsky were original leaders of the ImageNet database development.
This competition tested which algorithm best classified the images from the ImageNet Database. First conceived by the female computer scientist Fei-Fei Li, and eventually including other female researchers including Christiane Fellbaum and Olga Russakovsky, ImageNet is a database of human-labelled images. An assistant professor at Princeton, Li believed that a large database of images was necessary to advance “computer vision” (i.e., how computers can read, process, and analyze images). She initiated his huge project by meeting with Princeton professor Christiane Fellbaum, one of the creators of the word database WordNet (which has been criticized by linguists and scholars for its oversimplification of language, neglect of syntax and semantics, and irregularities of the lexicon).
From July 2008 to April 2010, Li’s team meticulously built ImageNet using nouns from WordNet to gather and then tediously classify over 14 million images. Each image was classified 3 times and ultimately required 49 thousand workers from 167 countries. The project was initially met with skepticism from the research community (likely predominantly male), who focused more on algorithm development rather than developing training data (historically women’s work).
Once the training data was developed, it was put to the test. In 2012, a competition (ImageNet Large Scale Visual Recognition Challenge (ILSVRC)) was held to determine which algorithm could best classify Flickr photos from one of 1000 possible object categories using the ImageNet database as training data.
The challenge was held in Florence, Italy, during the European Conference on Computer Vision. The challenge was initiated to bring widespread attention to ImageNet, promote Computer Vision (The “Holy Grail” of Recognition being Recognizing everything in the visual world) and promote algorithmic developments. There were 30 submissions in total and programs with lower error rate, accuracy of predictions, and consistency over several different trials were considerations. The top 3 programs were all neural network based, propelling the NN to fame.
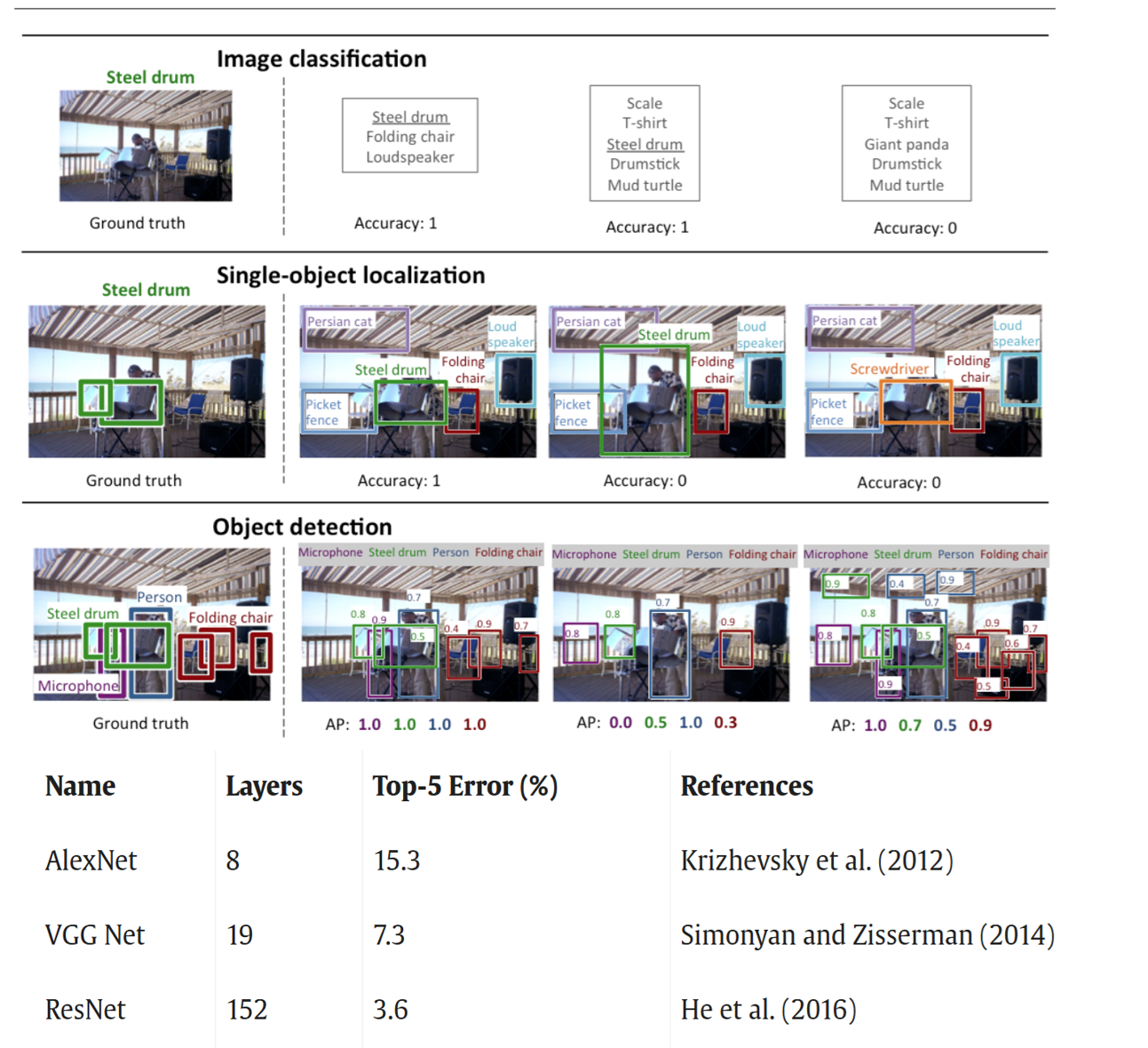
Top: How classification was used in the competition (Russakovsky et al 2014). Top 3 algorithms in the ImageNet competition. The “winning” algorithm “ALEXNET’ (It had the most consistently low error rate) were developed by 3 men Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton (Hinton won the 2024 Nobel Prize in Physics). The other 2 (VGG Net and ResNET) were also neural network-based and those coauthors listed were male.
Are Neural Networks More Susceptible to Bias?
As the 2010s proceeded, new hardware facilitated the use of NNs (now rebranded as “deep learning”). While a standard computer could process, 1010 operations per second, NNs on special hardware could process between 1014 and 1017 operations per second!
By the mid 2010s, platforms were eager to add NNs. NNs are unique because they are designed to build “connections” and favored “pathways” based on prior selection. Since 2016, YouTube provides recommended videos based on viewer’s history via NNs. This may seem harmless, if one were recommended songs based on a preferred music artist. However, problematic conspiracy-theory or inflammatory content which garners “likes” and views, reinforces the pathways in the neural net that recommend this content.
More discouraging is the increasing popularity of so-called “Asymmetric” neural networks (designed to resemble the so-called “male brain”), which have uneven weights and inputs. They have gained popularity in deep learning and AI applications. However, asymmetry in NNs is more likely to propagate bias than symmetric NNs.
Therefore, high rates of engagement and certain types of videos can be localized to certain videos. Earlier research in brain science used to try to pinpoint behavioral expression to localized areas in the brain. As I wrote previously, this has been proven to be too simplistic of how the brain works. NNs, though assume that certain groups of neurons are responsible for certain outputs. NNs when integrated into social media applications, concentrate and localize engagement to certain videos. They steer users to certain posts/areas of the platform. This can be especially dangerous when said content is erroneous, inflammatory, or hate-filled. These algorithms can ‘learn’ that user engagement can be driven by hateful content
The data NNs are trained on is also a source of bias. It’s the old “garbage in, garbage out” theory. If a dataset is flawed, biased, or unbalanced, then the model will perceive this imbalance. A source of bias could be relatively innocuous. For example, if I developed a survey whether people liked a certain movie, and collected data on their jobs, preferences, occupations, but I sample 50 men, and 10 women, then the responses really reflect men’s preferences. When I train my model and then use it to predict a movie score, it is training off of men’s data not women’s.
However, many platforms (notably ChatGTP) containing NNs are being trained on racialized and sexualized images of women online. This can perpetuate sexist and racist stereotypes, which can problematically infiltrate online chatbots and disturbingly harm users. In can affect grading, assigning higher grades to the ‘stereotype’ of high-performing students. With biased datasets, chatbots will be reinforced to biased responses in the areas of crime, history, medicine. It also creates false ‘benchmarks’ of the ‘typical’ human face (usually light-skinned) and the models are optimized to this benchmark.
A gleeful 2019 article from The MIT Technology Review stated that “Facebook has a neural network that can do advanced math”. Guillaume Lample and François Charton at Facebook AI Research in Paris developed an algorithm to differentiate and integrate (Calculus operations) mathematical expressions “for the first time”. The MIT Review notes that “The work is a significant step toward more powerful mathematical reasoning and a new way of applying neural networks beyond traditional pattern-recognition tasks”. However, the algorithm is not actually differentiating and integrating like a human would, instead, they “have come up with an elegant way to unpack mathematical shorthand into its fundamental units. They then teach a neural network to recognize the patterns of mathematical manipulation that are equivalent to integration and differentiation”
Neural Networks also had an attraction because they are perceived as imitating the human brain. Playing into fantasies of humanoid computers and robots, it’s like putting a “brain” inside a computer to replicate the human thought process. The enmeshment of NNs in current platforms like ChatGPT and generative AI platforms that assume humanoid characteristics is creating a fantasy of how the human brain should be: mysterious, and unapproachable, unquestionable in its superiority.
Neural Networks are a particularly addictive algorithm
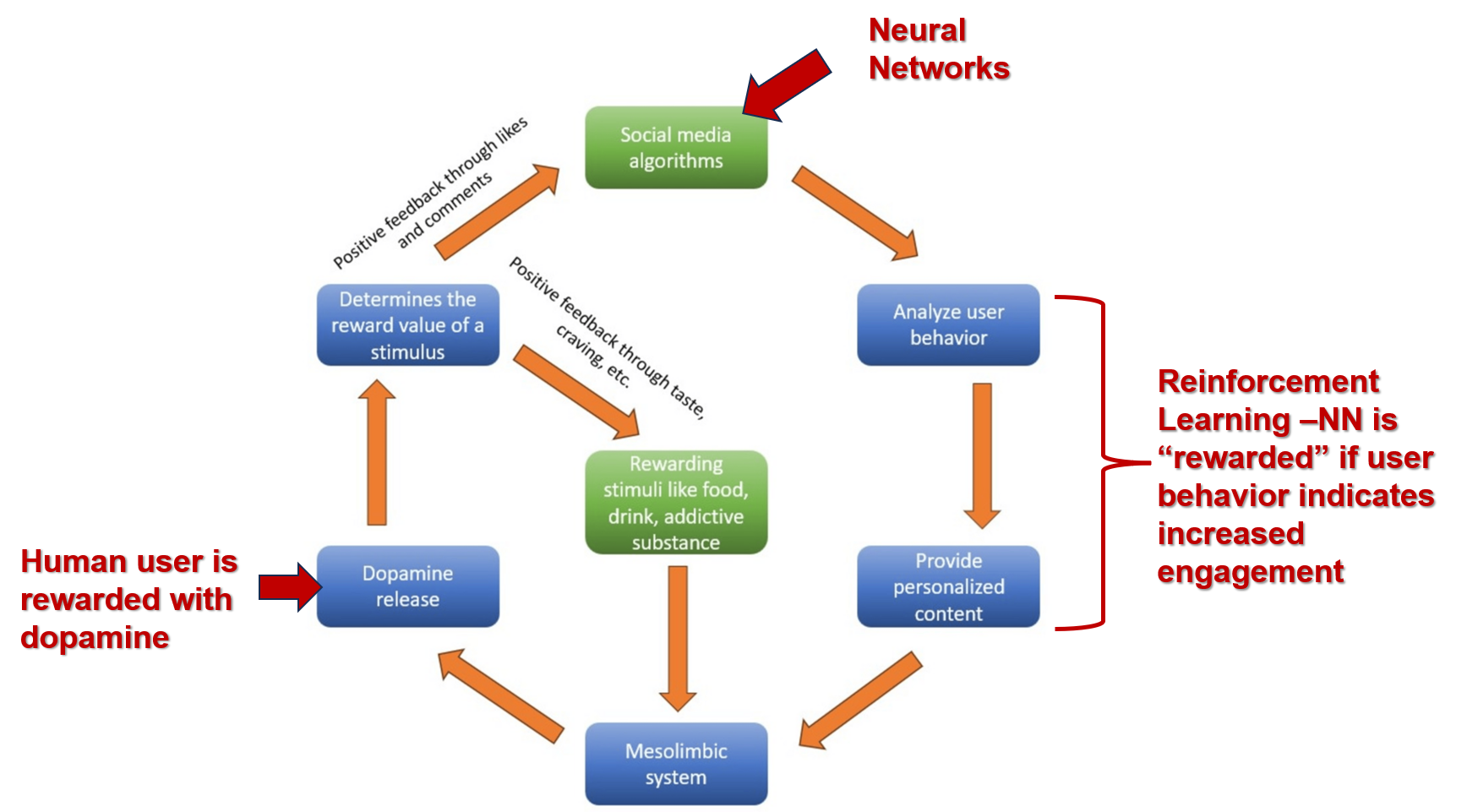
Cycle of addiction promoted by social media algorithms as described by De et al 2025. I added the red notes & arrows to indicate where the NNs come in. Mesolimbic system = brain reward system. Both the NN and the human are ‘rewarded’ in this cycle.
These platforms thrive on manipulating user behavior. The goal is to get them hooked, to keep them clicking and if their behavior does not satisfy the algorithm, the algorithm can change to try to get the user hooked.
The trigger for changing the connections is usually a discrepancy between the activity at the upper layer (output) and a ‘desired’ output, which has to be provided to the network during learning (‘supervised learning’). In the feedback networks information can propagate in loops within a layer or be transferred from higher to lower layers. Such networks allow learning without the need for a reward or any ‘teaching signal’ (‘unsupervised learning’). A combination of both architectures has been introduced in some models
More and more recommendations pop up in the feed. Watching 1 video, viewing one post, leads to viewing more and more until time has flown by.
For example, Substack provides emails and updates and a dashboard of site traffic, clicks, and open rates on articles. They are meant to encourage you to change your behavior, to post more, to click more, to get you engaging on the platform so your traffic rates, comments, likes, increase. As Joy V writes on her Substack “Endless scrolling/streaming (it’s hard to make the experience “end”) and we are primed to look for notifications, likes, and to keep scrolling.
Multiple articles and studies have shown the detriment of social media addiction on mental health, but few have linked them to this pernicious algorithm designed to mimic the human brain: neural networks.